mysql数据库优化
1.先说说数据库三范式
1.1 第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
1.2 第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
1.3 第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
2.准备测试数据库
2.1 下载sakila数据库
2.2 开启慢查询日志
1 | #查询是否开启慢查日志 |
3.慢查日志分析工具
3.1 mysqldumpslow
- 查前三条
mysqldumpslow -t 3 /www/wdlinux/mysql-5.1.69/var/oracledb-slow.log | more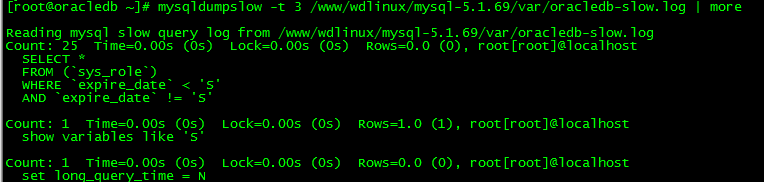
3.2 pt-query-digest
percona-toolkit的rpm安装方式
- 注意:需要安装Term::ReadKey 包,否则会报perl(Term::ReadKey) >= 2.10 is needed by percona-toolkit-2.1.1-1.noarch错误 **
1
2rpm -ivh perl-TermReadKey-2.30-1.el5.rf.x86_64.rpm
rpm -ivh percona-toolkit-2.1.1-1.noarch.rpm
- 注意:需要安装Term::ReadKey 包,否则会报perl(Term::ReadKey) >= 2.10 is needed by percona-toolkit-2.1.1-1.noarch错误 **
percona-toolkit的编译安装方式
- 下载安装包 **
1
2
3
4tar xzvf percona-toolkit-2.1.1.tar.gz
cd percona-toolkit-2.1.1
perl Makefile.PL
make && make install
- 下载安装包 **
查询日志
pt-query-digest /www/wdlinux/mysql-5.1.69/var/oracledb-slow.log | more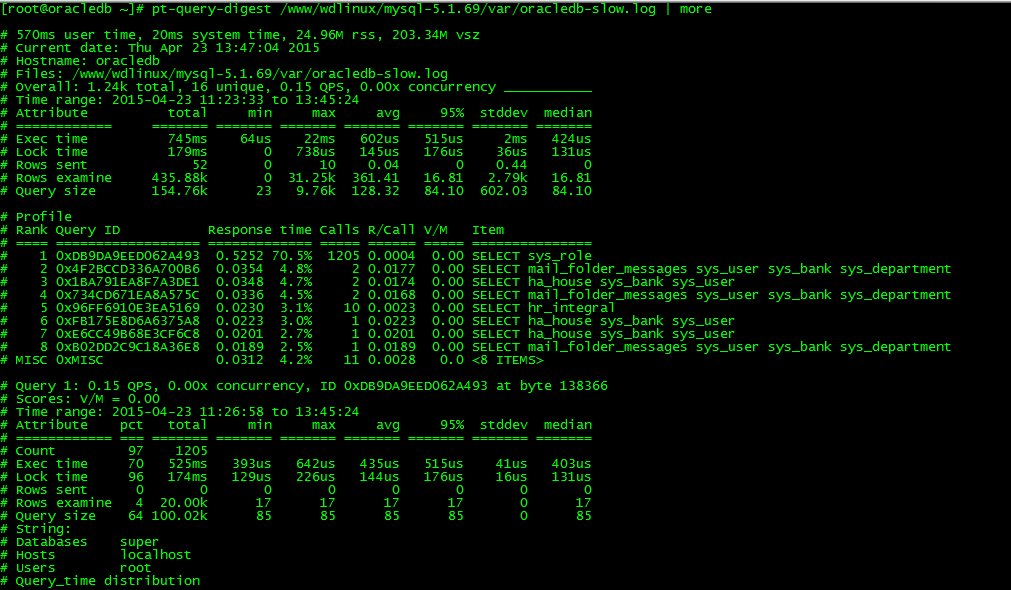
4.SQL优化
4.1索引优化
1 | #查询最大值:max(),建该字段索引 |
4.2 子查询优化
1 | #在t1表再插入一条数据已存在数据,那么t对t1表存在一对多的关系,子查询不会产生重复数据,但关联查询会产生重复数据,用distinct考虑去重! |
4.3 group by优化
1 | #原SQL |
4.4 limit优化
1 | #原SQL |
5.数据库优化
5.1数据库结构优化
选择合适的数据类型:int 类型比varchar更优,字段尽量设置为not null,并给默认值。
使用int来存储日期时间,利用from_unixtime(),unix_timestamp()两个函数来进行转换。
1
2Create table test(id int auto_increment not null ,timestr int ,primary key (id) );
Insert into test(timestr) values (unix_timestamp(‘2015-04-24 15:36:12’));用bigint存IP地址:利用inet_aton(),inet_ntoa()两个函数来进行转换
1
2
3Create table sessions( id int auto_increment not null, ip bigint, primary key (id));
Insert into sessions (ip) values (inet_aton(‘182.92.66.106’));
Select inet_ntoa(ip) from sessions;
5.2表的垂直拆分
- 把一个有很多列的表拆分成多个表,解决表的宽度问题。
1.把不常用的字段单独存放到一个表。
2.把大字段独立存放到一个表。
3.把经常使用的字段放到一起。
5.3表的水平拆分
- 解决单表数据量过大问题,水平拆分的表结构一样。
1.对表的某个字段(如:id)进行hash运算,如果要拆分成5个表则使用mod(id,5)取出0-4个值!
2.针对不同的hashID把数据存到不同的表中。
原文作者: ybphp
原文链接: https://www.ybphp.com/2016/04/24/mysql数据库优化/
版权声明: 转载请注明出处(必须保留原文作者署名原文链接)
